AWS Glue DataBrew, a visible knowledge preparation software, now permits customers to establish and deal with delicate knowledge by making use of superior transformations like redaction, substitute, encryption, and decryption on their personally identifiable data (PII) knowledge, and different sorts of knowledge they deem delicate. With exponential progress of information, firms are dealing with large volumes and all kinds of information coming into their platform, together with PII knowledge. Figuring out and defending delicate knowledge at scale has grow to be more and more complicated, costly, and time-consuming. Organizations have to stick to knowledge privateness, compliance, and regulatory wants equivalent to GDPR and CCPA. They should establish delicate knowledge, together with PII equivalent to title, SSN, tackle, e mail, driver’s license, and extra. Even after identification, it’s cumbersome to implement redaction, masking, or encryption of delicate knowledge at scale.
To assist facilitate knowledge privateness and safety, DataBrew has launched PII statistics, which identifies PII columns and supply their knowledge statistics if you run a profile job in your dataset. Moreover, DataBrew has launched PII knowledge dealing with transformations, which allow you to use knowledge masking, encryption, decryption, and different operations in your delicate knowledge.
On this publish, we stroll by means of an answer by which we run a knowledge profile job to establish and recommend potential PII columns current in a dataset. Subsequent, we goal PII columns in a DataBrew undertaking and apply numerous transformations to deal with the delicate columns present within the dataset. Lastly, we run a DataBrew job to use the transformations on your complete dataset and retailer the processed, masked, and encrypted knowledge securely in Amazon Easy Storage Service (Amazon S3).
Answer overview
We use a public dataset that’s accessible for obtain at Artificial Affected person Data with COVID-19. The information hosted inside SyntheticMass has been generated by SyntheaTM, an open-source affected person inhabitants simulation made accessible by The MITRE Company.
Obtain the zipped file 10k_synthea_covid19_csv.zip for this resolution and unzip it domestically. The answer makes use of the dummy knowledge within the file affected person.csv to display knowledge redaction and encryption functionality. The file comprises 10,000 artificial affected person data in CSV format, together with PII columns like driver’s license, start date, tackle, SSN, and extra.
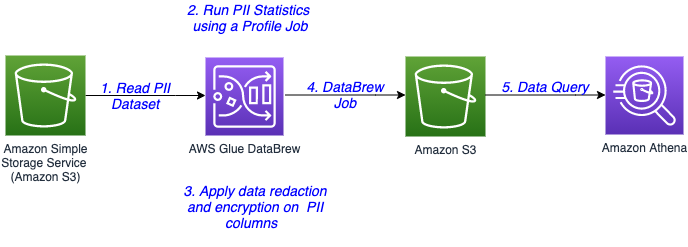
The next diagram illustrates the structure for our resolution.
The steps on this resolution are as follows:
- The delicate knowledge is saved in an S3 bucket. You create a DataBrew dataset by connecting to the information in Amazon S3.
- Run a DataBrew profile job to establish the PII columns current within the dataset by enabling PII statistics.
- After identification of PII columns, apply transformations to redact or encrypt column values as part of your recipe.
- A DataBrew job runs the recipe steps on your complete knowledge and generates output recordsdata with delicate knowledge redacted or encrypted.
- After the output knowledge is written to Amazon S3, we create an exterior desk on high in Amazon Athena. Information shoppers can use Athena to question the processed and cleaned knowledge.
Conditions
For this walkthrough, you want an AWS account. Use us-east-1 as your AWS Area to implement this resolution.
Arrange your supply knowledge in Amazon S3
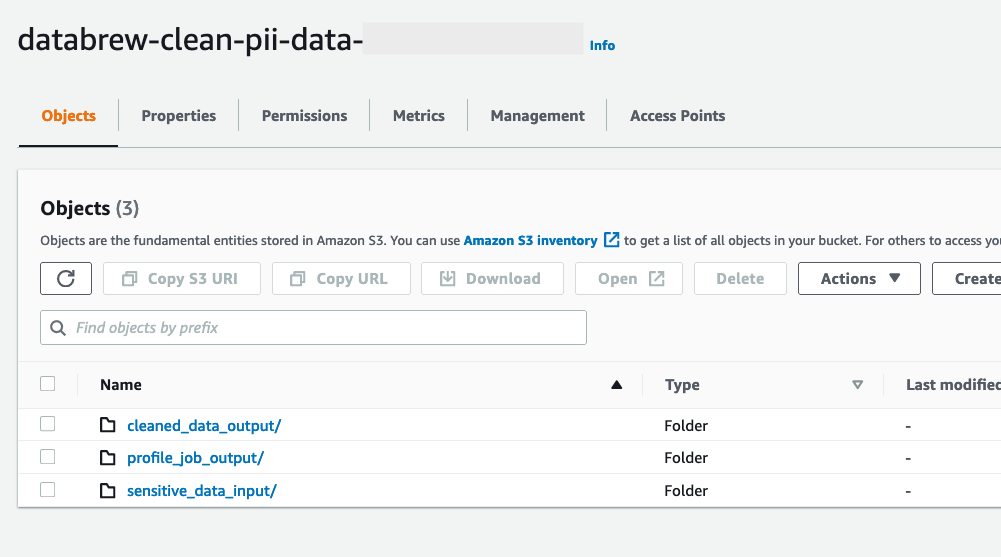
Create an S3 bucket referred to as databrew-clean-pii-data-<Your-Account-ID> in us-east-1 with the next prefixes:
sensitive_data_inputcleaned_data_outputprofile_job_output
Add the affected person.csv file to the sensitive_data_input prefix.
Create a DataBrew dataset
To create a DataBrew dataset, full the next steps:
- On the DataBrew console, within the navigation pane, select Datasets.
- Select Join new dataset.
- For Dataset title, enter a reputation (for this publish,
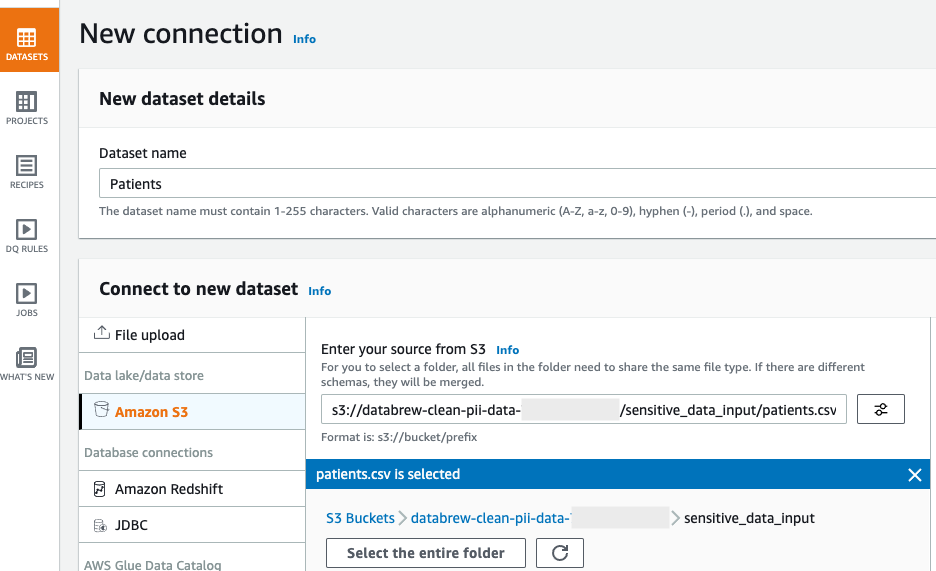
Sufferers). - Below Connect with new dataset, choose Amazon S3 as your supply.
- For Enter your supply from S3, enter the S3 path to the
affected person.csvfile. In our case, that iss3://databrew-clean-pii-data-<Account-ID>/ sensitive_data_input/sufferers.csv. - Scroll to the underside of the web page and select Create dataset.
Run a knowledge profile job
You’re now able to create your profile job.
- Within the navigation pane, select Datasets.
- Choose the
Sufferersdataset. - Select Run knowledge profile and select Create profile job.

- Title the job
Sufferers - Information Profile Job. - We run the information profile on your complete dataset, so for Information pattern, choose Full dataset.

- Within the Job output settings part, level to the
profile_job_outputS3 prefix the place the information profile output is saved when the job is full.
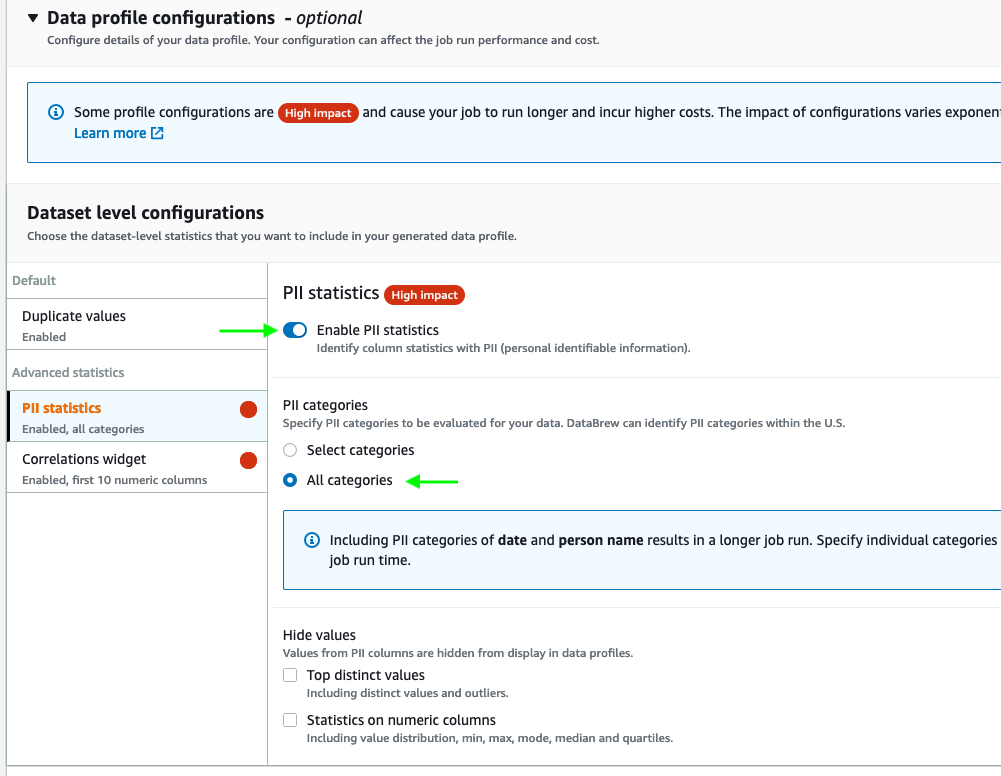
- Increase Information profile configurations, and choose Allow PII statistics to establish PII columns when operating the information profile job.
This feature is disabled by default; you should allow it manually earlier than operating the information profile job.
- For PII classes, choose All classes.
- Hold the remaining settings at their default.
- Within the Permissions part, create a brand new AWS Id and Entry Administration (IAM) function that’s utilized by the DataBrew job to run the profile job, and use
PII-DataBrew-Functionbecause the function suffix. - Select Create and run job.
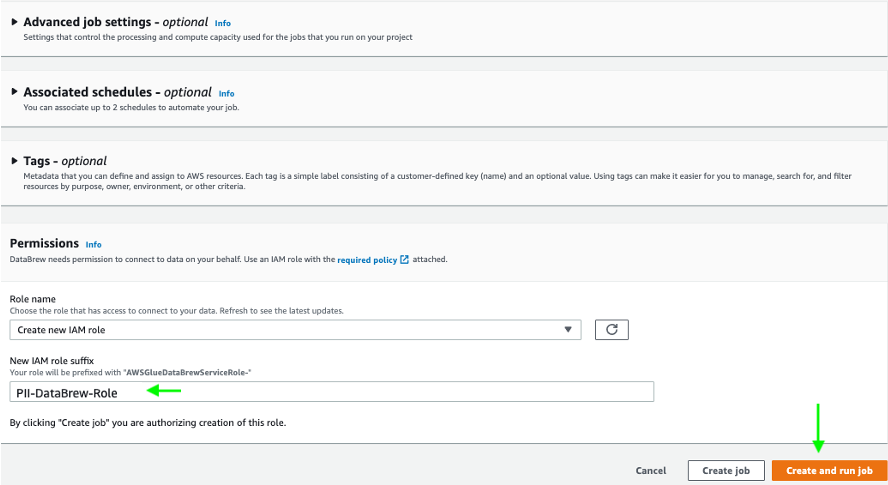
The job runs on the pattern knowledge and takes a couple of minutes to finish.
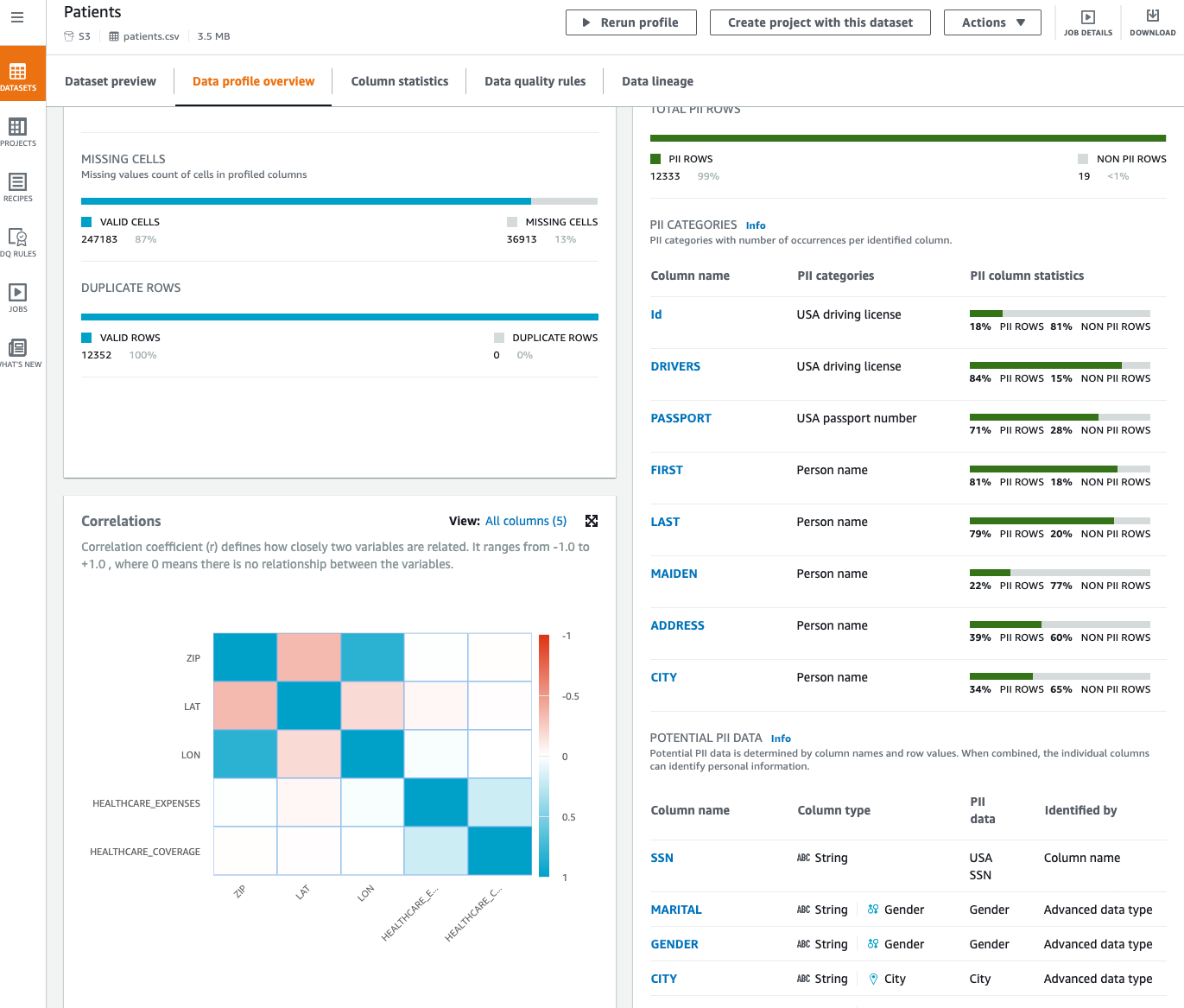
Now that we’ve run our profile job, we will evaluate knowledge profile insights about our dataset by selecting View knowledge profile. We will additionally evaluate the outcomes of the profile by means of the visualizations on the DataBrew console and think about the PII widget. This part supplies an inventory of recognized PII columns mapped to PII classes with column statistics. Moreover, it suggests potential PII knowledge you can evaluate.
Create a DataBrew undertaking
After we establish the PII columns in our dataset, we will concentrate on dealing with the delicate knowledge in our dataset. On this resolution, we carry out redaction and encryption in our DataBrew undertaking utilizing the Delicate class of transformations.
To create a DataBrew undertaking for dealing with our delicate knowledge, full the next steps:
- On the DataBrew console, select Tasks.
- Select Create undertaking.
- For Challenge title, enter a reputation (for this publish,
patients-pii-handling). - For Choose a dataset, choose My datasets.
- Choose the
Sufferersdataset.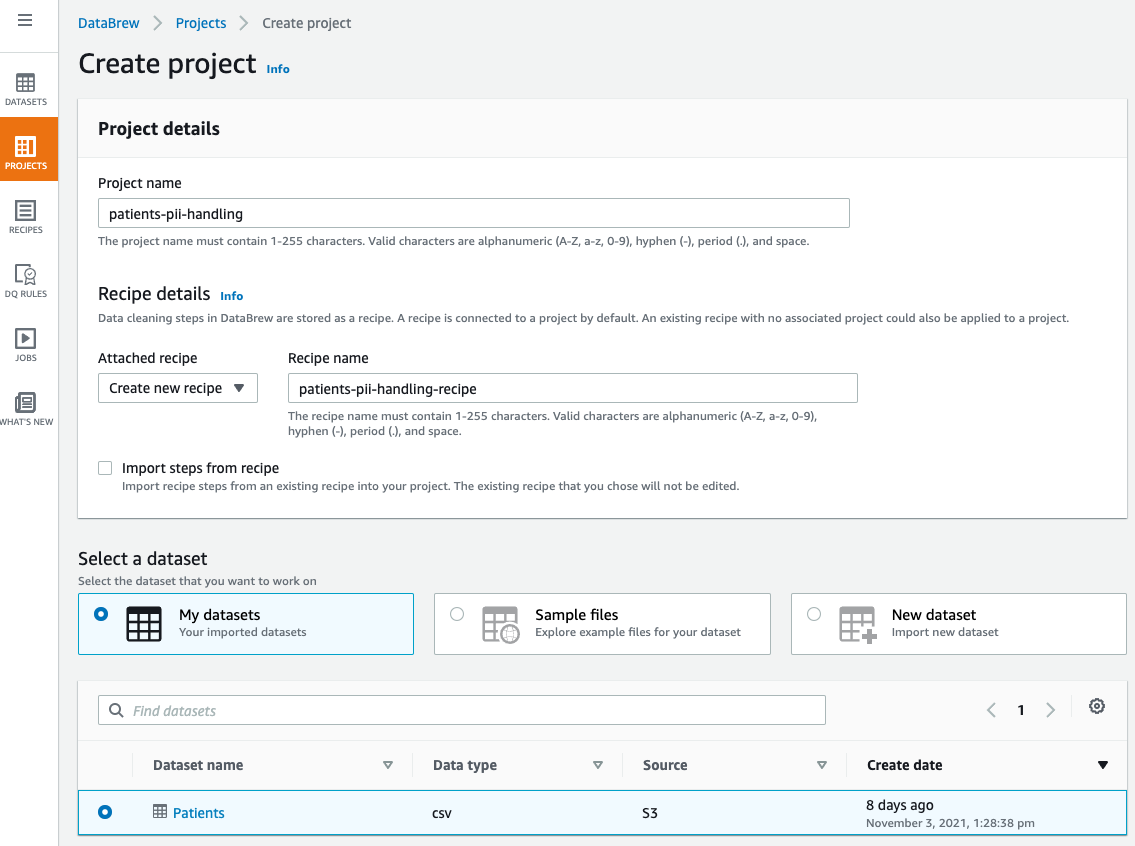
- Below Permissions, for Function title, select the IAM function that we created beforehand for our DataBrew profile job
AWSGlueDataBrewServiceRole-PII-DataBrew-Function. - Select Create undertaking.

The dataset takes couple of minutes to load. When the dataset is loaded, we will begin performing redactions. Allow us to begin with the column SSN.
- For the
SSNcolumn, on the Delicate menu, select Redact knowledge.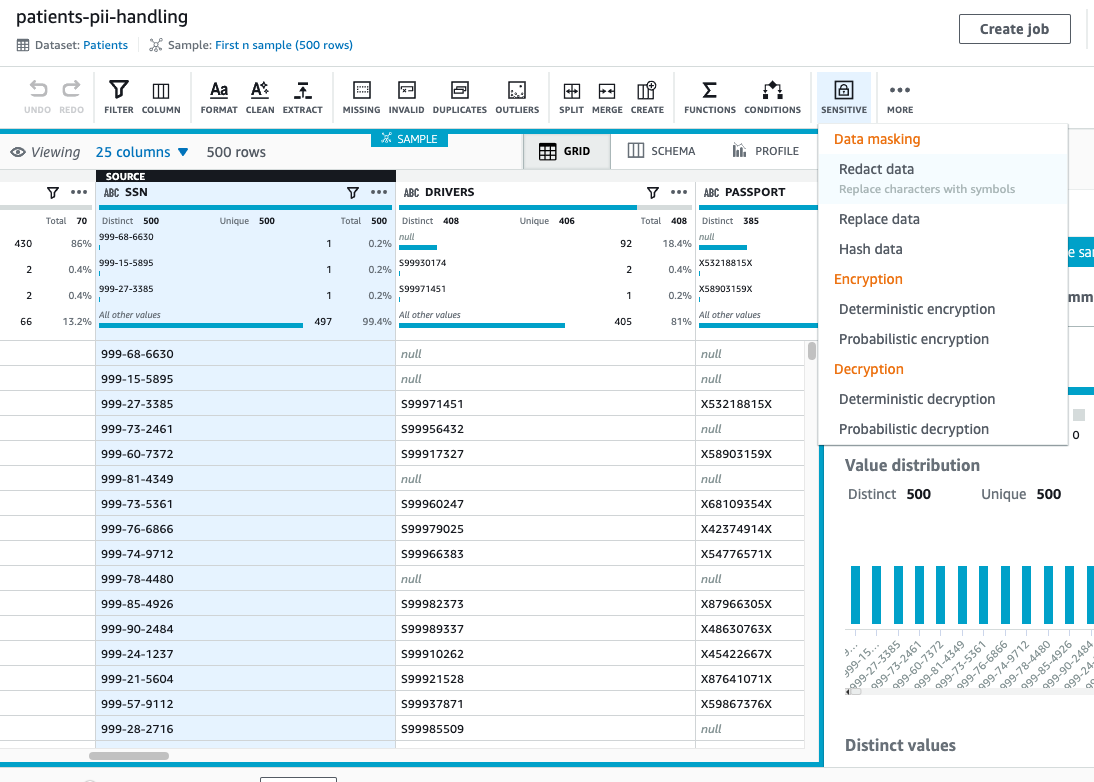
- Below Apply redaction, choose Full string worth.
- We redact all of the non-alphanumeric characters and change them with
#. - Select Preview modifications to check the redacted values.
- Select Apply.

On the Delicate menu, all the information masking transformations—redact, change, and hash knowledge—are irreversible. After we finalize our recipe and run the DataBrew job, the job output to Amazon S3 is completely redacted and we will’t recuperate it.
- Now, let’s apply redaction to a number of columns, assuming the next columns should not be consumed by any downstream customers like knowledge analyst, BI engineer, and knowledge scientist:
DRIVERSPASSPORTBIRTHPLACEADDRESSLATLON
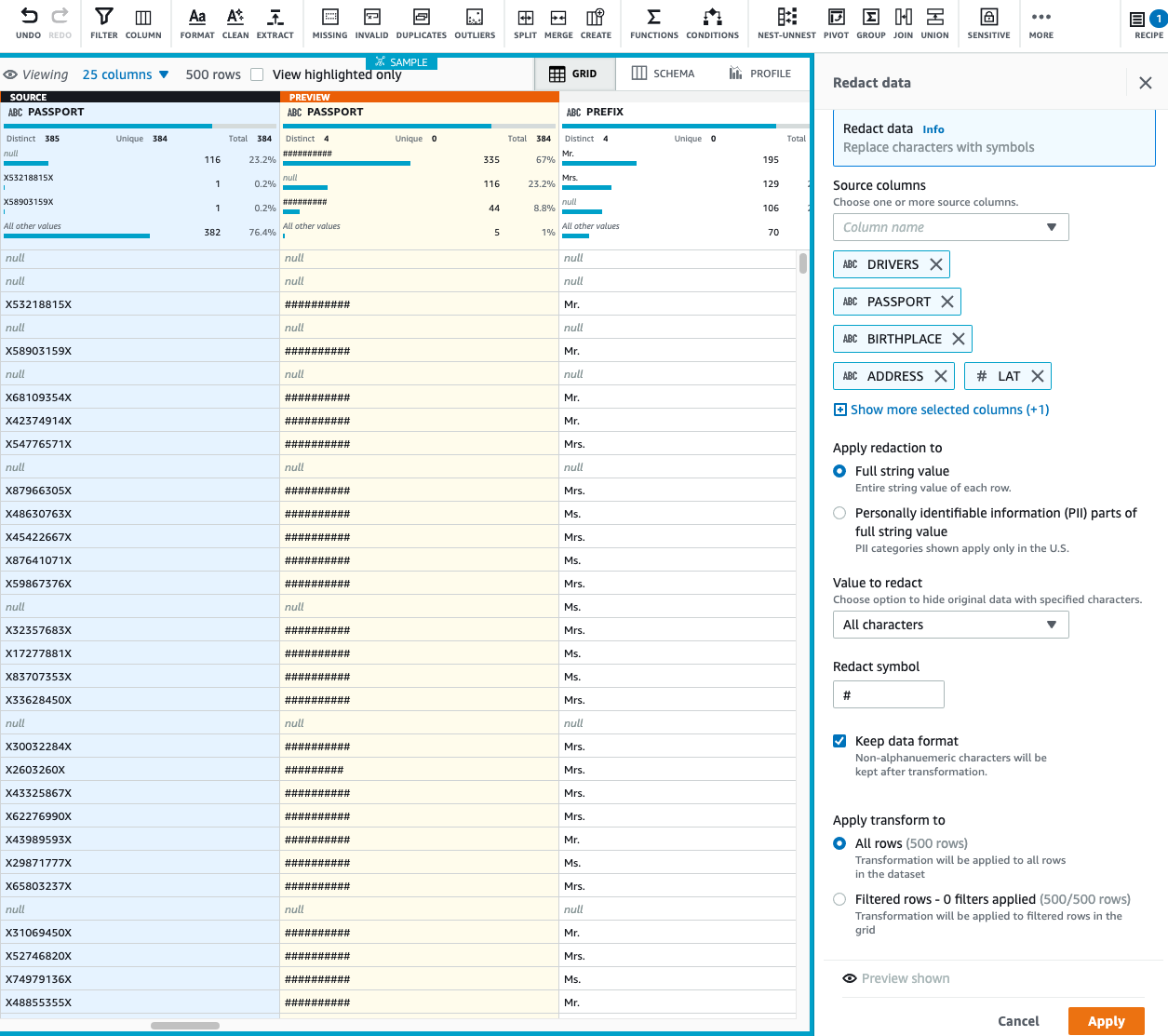
In particular instances, when we have to recuperate our delicate knowledge, as an alternative of masking, we will encrypt our column values and when wanted, decrypt the information to deliver it again to its unique format. Let’s assume we require a column worth to be decrypted by a downstream utility; in that case, we will encrypt our delicate knowledge.
Now we have two encryption choices: deterministic and probabilistic. To be used instances after we need to be a part of two datasets on the identical encrypted column, we should always apply deterministic encryption. It makes certain that the encrypted worth of all of the distinct values is identical throughout DataBrew initiatives so long as we use the identical AWS secret key. Moreover, remember the fact that if you apply deterministic encryption in your PII columns, you possibly can solely use DataBrew to decrypt these columns.
For our use case, let’s assume we need to carry out deterministic encryption on a couple of of our columns.
- On the Delicate menu, select Deterministic encryption.

- For Supply columns, choose BIRTHDATE, DEATHDATE, FIRST, and LAST.
- For Encryption choice, choose Deterministic encryption.
- For Choose secret, select the
databrew!defaultAWS secret.
- Select Apply.
- After you end making use of all of your transformations, select Publish.
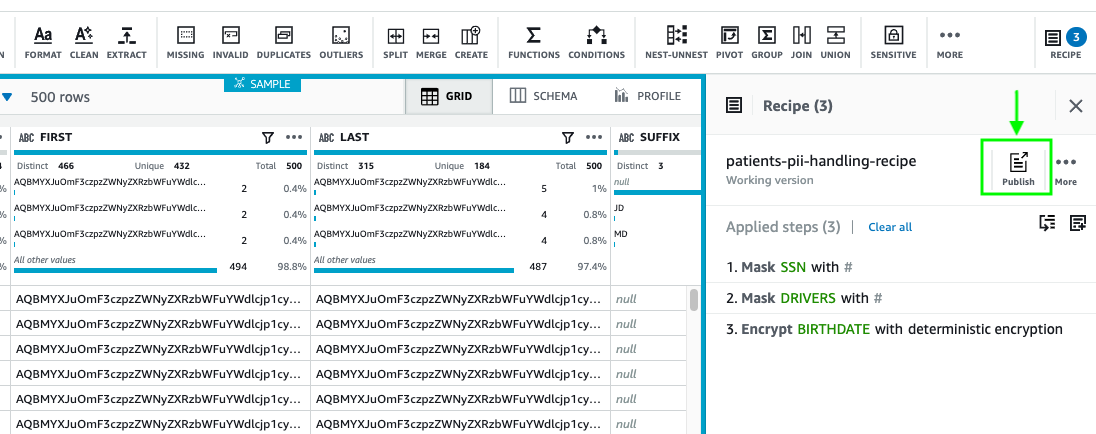
- Enter an outline for the recipe model and select Publish.


Create a DataBrew job
Now that our recipe is prepared, we will create a job to use the recipe steps to the Sufferers dataset.
- On the DataBrew console, select Jobs.
- Select Create a job.
- For Job title, enter a reputation (for instance,
Affected person PII Making and Encryption). - Choose the
Sufferersdataset and selectpatients-pii-handling-recipeas your recipe. - Below Job output settings¸ for File sort, select your closing storage format to be Parquet.
- For S3 location, enter your S3 output as
s3://databrew-clean-pii-data-<Account-ID>/cleaned_data_output/.
- For Compression, select None.
- For File output storage, choose Change output recordsdata for every job run.
- Below Permissions, for Function title¸ select the identical IAM function we used beforehand.
- Select Create and run job.
Create an Athena desk
You may create tables by writing the DDL assertion within the Athena question editor. Should you’re not accustomed to Apache Hive, it’s best to evaluate Creating Tables in Athena to learn to create an Athena desk that references the information residing in Amazon S3.
To create an Athena desk, use the question editor and enter the next DDL assertion:
Let’s validate the desk output in Athena by operating a easy SELECT question. The next screenshot exhibits the output.
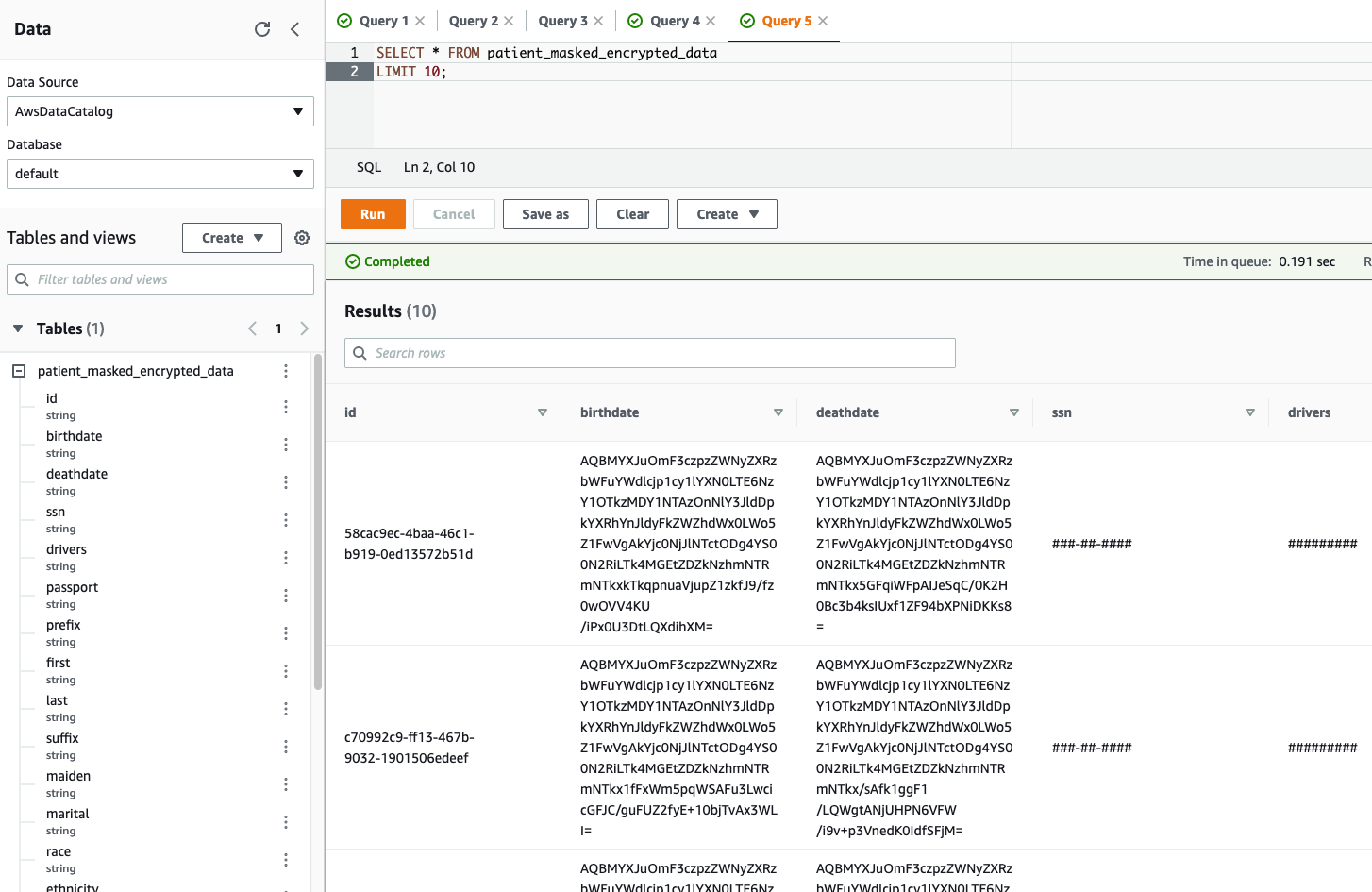
We will clearly see the encrypted and redacted column values in our question output.
Cleansing up
To keep away from incurring future fees, delete the sources created throughout this walkthrough.
Conclusion
As demonstrated on this publish, you should use DataBrew to assist establish, redact, and encrypt PII knowledge. With these new PII transformations, you possibly can streamline and simplify buyer knowledge administration throughout industries equivalent to monetary companies, authorities, retail, and way more.
DataBrew might help you shield your delicate knowledge workloads to satisfy regulatory and compliance finest practices, and you should use this resolution to construct de-identified knowledge lakes in AWS.De-identified knowledge lakes can allow delicate knowledge fields to stay protected all through their lifecycle, whereas non-sensitive knowledge fields stay seen. This strategy can permit analytics or different enterprise features to function on knowledge with out exposing delicate knowledge.
In regards to the Authors
 Harsh Vardhan Singh Gaur is an AWS Options Architect, specializing in Analytics. He has over 5 years of expertise working within the discipline of massive knowledge and knowledge science. He’s enthusiastic about serving to clients undertake finest practices and uncover insights from their knowledge.
Harsh Vardhan Singh Gaur is an AWS Options Architect, specializing in Analytics. He has over 5 years of expertise working within the discipline of massive knowledge and knowledge science. He’s enthusiastic about serving to clients undertake finest practices and uncover insights from their knowledge.
 Navnit Shukla is an AWS Specialist Answer Architect, Analytics, and is enthusiastic about serving to clients uncover insights from their knowledge. He has been constructing options to assist organizations make data-driven choices.
Navnit Shukla is an AWS Specialist Answer Architect, Analytics, and is enthusiastic about serving to clients uncover insights from their knowledge. He has been constructing options to assist organizations make data-driven choices.



