
Companies accumulate an increasing number of knowledge on daily basis to drive processes like decision-making, reporting, and machine studying (ML). Earlier than cleansing and reworking your knowledge, it’s essential decide whether or not it’s match to be used. Incorrect, lacking, or malformed knowledge can have massive impacts on downstream analytics and ML processes. Performing knowledge high quality checks helps determine points earlier in your workflow so you’ll be able to resolve them quicker. Moreover, doing these checks utilizing an event-based structure helps you scale back guide touchpoints and scale with rising quantities of information.
AWS Glue DataBrew is a visible knowledge preparation device that makes it straightforward to seek out knowledge high quality statistics similar to duplicate values, lacking values, and outliers in your knowledge. You can even arrange knowledge high quality guidelines in DataBrew to carry out conditional checks based mostly in your distinctive enterprise wants. For instance, a producer would possibly want to make sure that there are not any duplicate values particularly in a Half ID column, or a healthcare supplier would possibly examine that values in an SSN column are a sure size. After you create and validate these guidelines with DataBrew, you should use Amazon EventBridge, AWS Step Features, AWS Lambda, and Amazon Easy Notification Service (Amazon SNS) to create an automatic workflow and ship a notification when a rule fails a validation examine.
On this submit, we stroll you thru the end-to-end workflow and implement this resolution. This submit features a step-by-step tutorial, an AWS Serverless Utility Mannequin (AWS SAM) template, and instance code that you should use to deploy the applying in your individual AWS atmosphere.
Resolution overview
The answer on this submit combines serverless AWS providers to construct a totally automated, end-to-end event-driven pipeline for knowledge high quality validation. The next diagram illustrates our resolution structure.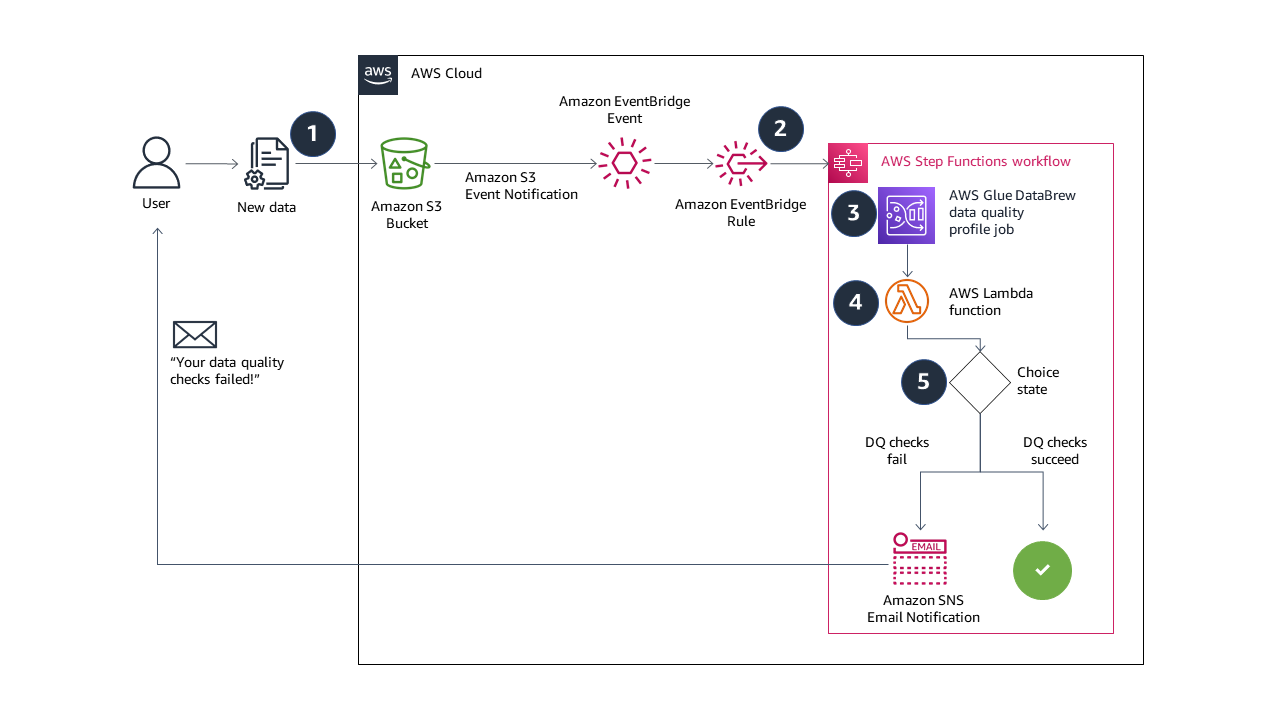
The answer workflow incorporates the next steps:
- While you add new knowledge to your Amazon Easy Storage Service (Amazon S3) bucket, occasions are despatched to EventBridge.
- An EventBridge rule triggers a Step Features state machine to run.
- The state machine begins a DataBrew profile job, configured with a knowledge high quality ruleset and guidelines. If you happen to’re contemplating constructing an identical resolution, the DataBrew profile job output location and the supply knowledge S3 buckets ought to be distinctive. This prevents recursive job runs. We deploy our sources with an AWS CloudFormation template, which creates distinctive S3 buckets.
- A Lambda perform reads the information high quality outcomes from Amazon S3, and returns a Boolean response into the state machine. The perform returns
falseif a number of guidelines within the ruleset fail, and returnstrueif all guidelines succeed. - If the Boolean response is
false, the state machine sends an e-mail notification with Amazon SNS and the state machine ends in afailedstanding. If the Boolean response istrue, the state machine ends in asucceedstanding. You can even prolong the answer on this step to run different duties on success or failure. For instance, if all the foundations succeed, you’ll be able to ship an EventBridge message to set off one other transformation job in DataBrew.
On this submit, you utilize AWS CloudFormation to deploy a completely functioning demo of the event-driven knowledge high quality validation resolution. You take a look at the answer by importing a sound comma-separated values (CSV) file to Amazon S3, adopted by an invalid CSV file.
The steps are as follows:
- Launch a CloudFormation stack to deploy the answer sources.
- Check the answer:
- Add a sound CSV file to Amazon S3 and observe the information high quality validation and Step Features state machine succeed.
- Add an invalid CSV file to Amazon S3 and observe the information high quality validation and Step Features state machine fail, and obtain an e-mail notification from Amazon SNS.
All of the pattern code may be discovered within the GitHub repository.
Stipulations
For this walkthrough, it’s best to have the next stipulations:
Deploy the answer sources utilizing AWS CloudFormation
You employ a CloudFormation stack to deploy the sources wanted for the event-driven knowledge high quality validation resolution. The stack consists of an instance dataset and ruleset in DataBrew.
- Register to your AWS account after which select Launch Stack:

- On the Fast create stack web page, for EmailAddress, enter a sound e-mail tackle for Amazon SNS e-mail notifications.
- Depart the remaining choices set to the defaults.
- Choose the acknowledgement examine bins.
- Select Create stack.

The CloudFormation stack takes about 5 minutes to achieve CREATE_COMPLETE standing.
- Test the inbox of the e-mail tackle you supplied and settle for the SNS subscription.
You could overview and settle for the subscription affirmation with a view to display the e-mail notification function on the finish of the walkthrough.
On the Outputs tab of the stack, you will discover the URLs to browse the DataBrew and Step Features sources that the template created. Additionally notice the finished AWS CLI instructions you utilize in later steps.
If you happen to select the AWSGlueDataBrewRuleset worth hyperlink, it’s best to see the ruleset particulars web page, as within the following screenshot. On this walkthrough, we create a knowledge high quality ruleset with three guidelines that examine for lacking values, outliers, and string size.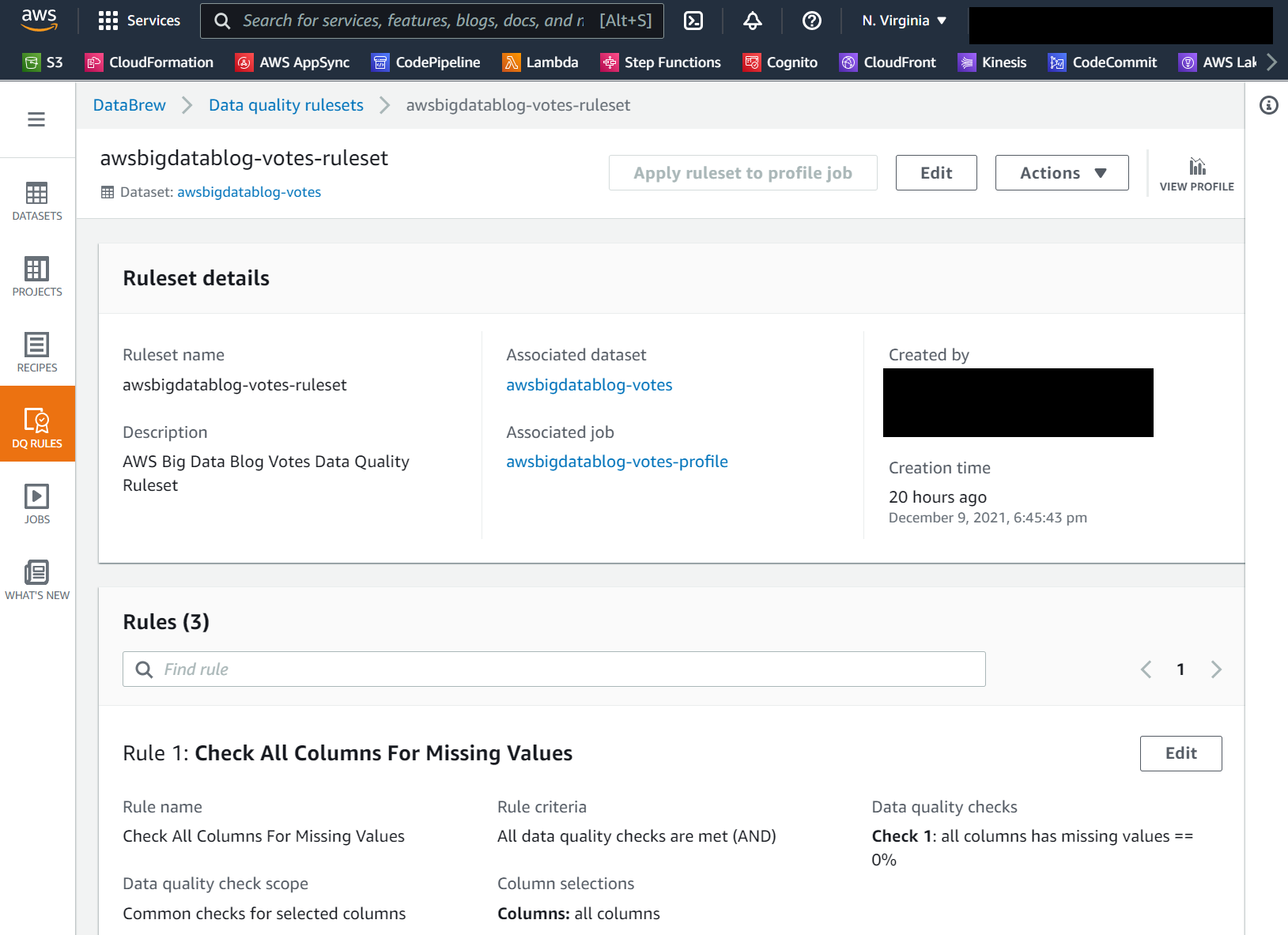
Check the answer
Within the following steps, you utilize the AWS CLI to add appropriate and incorrect variations of the CSV file to check the event-driven knowledge high quality validation resolution.
- Open a terminal or command line immediate and use the AWS CLI to obtain pattern knowledge. Use the command from the CloudFormation stack output with the important thing title
CommandToDownloadTestData: - Use the AWS CLI once more to add the unchanged CSV file to your S3 bucket. Substitute the string <your_bucket> along with your bucket title, or copy and paste the command supplied to you from the CloudFormation template output:
- On the Step Features console, find the state machine created by the CloudFormation template.
Yow will discover a URL within the CloudFormation outputs famous earlier.
- On the Executions tab, it’s best to see a brand new run of the state machine.
- Select the run’s URL to view the state machine graph and monitor its progress.

The next picture reveals the workflow of our state machine.
To display a knowledge high quality rule’s failure, you make a minimum of one edit to the votes.csv file.
- Open the file in your most popular textual content editor or spreadsheet device, and delete only one cell.
Within the following screenshots, I take advantage of the GNU nano editor on Linux. You can even use a spreadsheet editor to delete a cell. This causes the “Test All Columns For Lacking Values” rule to fail.
The next screenshot reveals the CSV file earlier than modification.
The next screenshot reveals the modified CSV file.
- Save the edited
votes.csvfile and return to your command immediate or terminal. - Use the AWS CLI to add the file to your S3 bucket another time. You employ the identical command as earlier than:
- On the Step Features console, navigate to the most recent state machine run to watch it.
The info high quality validation fails, triggering an SNS e-mail notification and the failure of the general state machine’s run.
The next picture reveals the workflow of the failed state machine.
The next screenshot reveals an instance of the SNS e-mail.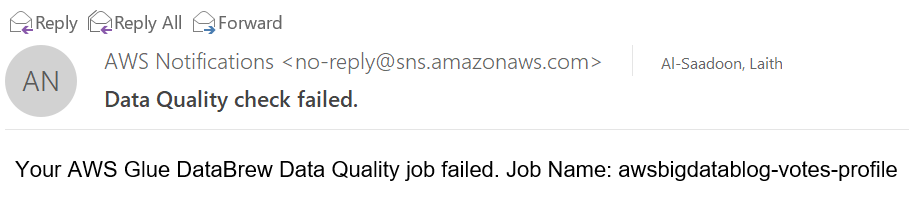
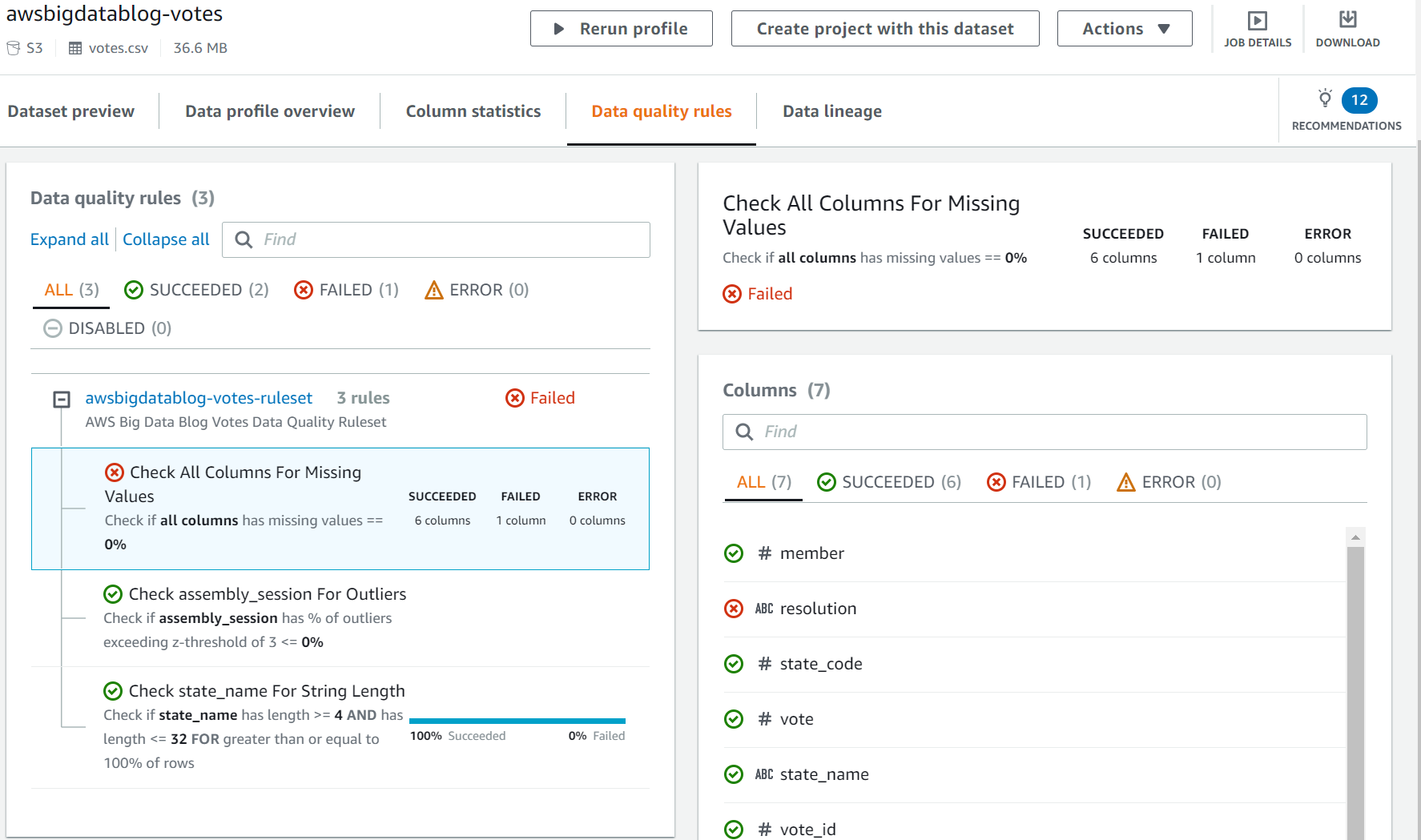
- You possibly can examine the rule failure on the DataBrew console by selecting the
AWSGlueDataBrewProfileResultsworth within the CloudFormation stack outputs.
Clear up
To keep away from incurring future expenses, delete the sources. On the AWS CloudFormation console, delete the stack named AWSBigDataBlogDataBrewDQSample.
Conclusion
On this submit, you discovered construct automated, event-driven knowledge high quality validation pipelines. With DataBrew, you’ll be able to outline knowledge high quality guidelines, thresholds, and rulesets for your enterprise and technical necessities. Step Features, EventBridge, and Amazon SNS mean you can construct advanced pipelines with customizable error dealing with and alerting tailor-made to your wants.
You possibly can study extra about this resolution and the supply code by visiting the GitHub repository. To study extra about DataBrew knowledge high quality guidelines, go to AWS Glue DataBrew now permits prospects to create knowledge high quality guidelines to outline and validate their enterprise necessities or consult with Validating knowledge high quality in AWS Glue DataBrew.
Concerning the Authors
 Laith Al-Saadoon is a Principal Prototyping Architect on the Envision Engineering group. He builds prototypes and options utilizing AI, machine studying, IoT & edge computing, streaming analytics, robotics, and spatial computing to resolve real-world buyer issues. In his free time, Laith enjoys out of doors actions similar to pictures, drone flights, mountain climbing, and paintballing.
Laith Al-Saadoon is a Principal Prototyping Architect on the Envision Engineering group. He builds prototypes and options utilizing AI, machine studying, IoT & edge computing, streaming analytics, robotics, and spatial computing to resolve real-world buyer issues. In his free time, Laith enjoys out of doors actions similar to pictures, drone flights, mountain climbing, and paintballing.
 Gordon Burgess is a Senior Product Supervisor with AWS Glue DataBrew. He’s captivated with serving to prospects uncover insights from their knowledge, and focuses on constructing person experiences and wealthy performance for analytics merchandise. Outdoors of labor, Gordon enjoys studying, espresso, and constructing computer systems.
Gordon Burgess is a Senior Product Supervisor with AWS Glue DataBrew. He’s captivated with serving to prospects uncover insights from their knowledge, and focuses on constructing person experiences and wealthy performance for analytics merchandise. Outdoors of labor, Gordon enjoys studying, espresso, and constructing computer systems.



